Quantization¶
Warning
Quantization is in beta and subject to change.
Introduction to Quantization¶
Quantization refers to techniques for performing computations and storing tensors at lower bitwidths than floating point precision. A quantized model executes some or all of the operations on tensors with integers rather than floating point values. This allows for a more compact model representation and the use of high performance vectorized operations on many hardware platforms. PyTorch supports INT8 quantization compared to typical FP32 models allowing for a 4x reduction in the model size and a 4x reduction in memory bandwidth requirements. Hardware support for INT8 computations is typically 2 to 4 times faster compared to FP32 compute. Quantization is primarily a technique to speed up inference and only the forward pass is supported for quantized operators.
PyTorch supports multiple approaches to quantizing a deep learning model. In most cases the model is trained in FP32 and then the model is converted to INT8. In addition, PyTorch also supports quantization aware training, which models quantization errors in both the forward and backward passes using fake-quantization modules. Note that the entire computation is carried out in floating point. At the end of quantization aware training, PyTorch provides conversion functions to convert the trained model into lower precision.
At lower level, PyTorch provides a way to represent quantized tensors and perform operations with them. They can be used to directly construct models that perform all or part of the computation in lower precision. Higher-level APIs are provided that incorporate typical workflows of converting FP32 model to lower precision with minimal accuracy loss.
Today, PyTorch supports the following backends for running quantized operators efficiently:
x86 CPUs with AVX2 support or higher (without AVX2 some operations have inefficient implementations)
ARM CPUs (typically found in mobile/embedded devices)
The corresponding implementation is chosen automatically based on the PyTorch build mode.
Note
PyTorch 1.3 doesn’t provide quantized operator implementations on CUDA yet - this is direction of future work. Move the model to CPU in order to test the quantized functionality.
Quantization-aware training (through FakeQuantize)
supports both CPU and CUDA.
Note
When preparing a quantized model, it is necessary to ensure that qconfig and the engine used for quantized computations match the backend on which the model will be executed. Quantization currently supports two backends: fbgemm (for use on x86, https://github.com/pytorch/FBGEMM) and qnnpack (for use on the ARM QNNPACK library https://github.com/pytorch/QNNPACK). For example, if you are interested in quantizing a model to run on ARM, it is recommended to set the qconfig by calling:
qconfig = torch.quantization.get_default_qconfig('qnnpack')
for post training quantization and
qconfig = torch.quantization.get_default_qat_qconfig('qnnpack')
for quantization aware training.
In addition, the torch.backends.quantized.engine parameter should be set to match the backend. For using qnnpack for inference, the backend is set to qnnpack as follows
torch.backends.quantized.engine = 'qnnpack'
Quantized Tensors¶
PyTorch supports both per tensor and per channel asymmetric linear quantization. Per tensor means that all the values within the tensor are scaled the same way. Per channel means that for each dimension, typically the channel dimension of a tensor, the values in the tensor are scaled and offset by a different value (effectively the scale and offset become vectors). This allows for lesser error in converting tensors to quantized values.
The mapping is performed by converting the floating point tensors using
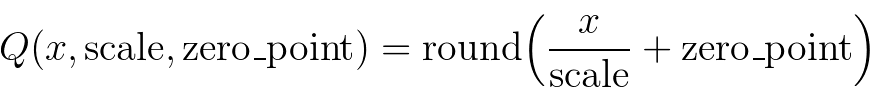
Note that, we ensure that zero in floating point is represented with no error after quantization, thereby ensuring that operations like padding do not cause additional quantization error.
In order to do quantization in PyTorch, we need to be able to represent quantized data in Tensors. A Quantized Tensor allows for storing quantized data (represented as int8/uint8/int32) along with quantization parameters like scale and zero_point. Quantized Tensors allow for many useful operations making quantized arithmetic easy, in addition to allowing for serialization of data in a quantized format.
Operation coverage¶
Quantized Tensors support a limited subset of data manipulation methods of the regular full-precision tensor. (see list below)
For NN operators included in PyTorch, we restrict support to:
8 bit weights (data_type = qint8)
8 bit activations (data_type = quint8)
Note that operator implementations currently only support per channel quantization for weights of the conv and linear operators. Furthermore the minimum and the maximum of the input data is mapped linearly to the minimum and the maximum of the quantized data type such that zero is represented with no quantization error.
Additional data types and quantization schemes can be implemented through the custom operator mechanism.
Many operations for quantized tensors are available under the same API as full
float version in torch or torch.nn. Quantized version of NN modules that
perform re-quantization are available in torch.nn.quantized. Those
operations explicitly take output quantization parameters (scale and zero_point) in
the operation signature.
In addition, we also support fused versions corresponding to common fusion patterns that impact quantization at: torch.nn.intrinsic.quantized.
For quantization aware training, we support modules prepared for quantization aware training at torch.nn.qat and torch.nn.intrinsic.qat
Current quantized operation list is sufficient to cover typical CNN and RNN models:
Quantized torch.Tensor operations¶
Operations that are available from the torch namespace or as methods on
Tensor for quantized tensors:
quantize_per_tensor()- Convert float tensor to quantized tensor with per-tensor scale and zero pointquantize_per_channel()- Convert float tensor to quantized tensor with per-channel scale and zero pointView-based operations like
view(),as_strided(),expand(),flatten(),select(), python-style indexing, etc - work as on regular tensor (if quantization is not per-channel)copy_()— Copies src to self in-placeclone()— Returns a deep copy of the passed-in tensordequantize()— Convert quantized tensor to float tensorequal()— Compares two tensors, returns true if quantization parameters and all integer elements are the sameint_repr()— Prints the underlying integer representation of the quantized tensormax()— Returns the maximum value of the tensor (reduction only)mean()— Mean function. Supported variants: reduction, dim, outmin()— Returns the minimum value of the tensor (reduction only)q_scale()— Returns the scale of the per-tensor quantized tensorq_zero_point()— Returns the zero_point of the per-tensor quantized zero pointq_per_channel_scales()— Returns the scales of the per-channel quantized tensorq_per_channel_zero_points()— Returns the zero points of the per-channel quantized tensorq_per_channel_axis()— Returns the channel axis of the per-channel quantized tensorresize_()— In-place resizesort()— Sorts the tensortopk()— Returns k largest values of a tensor
torch.nn.functional¶
Basic activations are supported.
relu()— Rectified linear unit (copy)relu_()— Rectified linear unit (inplace)elu()- ELUmax_pool2d()- Maximum poolingadaptive_avg_pool2d()- Adaptive average poolingavg_pool2d()- Average poolinginterpolate()- Interpolationhardsigmoid()- Hardsigmoidhardswish()- Hardswishhardtanh()- Hardtanhupsample()- Upsamplingupsample_bilinear()- Bilinear Upsamplingupsample_nearest()- Upsampling Nearest
torch.nn.intrinsic¶
Fused modules are provided for common patterns in CNNs. Combining several operations together (like convolution and relu) allows for better quantization accuracy
torch.nn.intrinsic— float versions of the modules, can be swapped with quantized version 1 to 1:ConvBn1d— Conv1d + BatchNorm1dConvBn2d— Conv2d + BatchNormConvBnReLU1d— Conv1d + BatchNorm1d + ReLUConvBnReLU2d— Conv2d + BatchNorm + ReLUConvReLU1d— Conv1d + ReLUConvReLU2d— Conv2d + ReLUConvReLU3d— Conv3d + ReLULinearReLU— Linear + ReLU
torch.nn.intrinsic.qat— versions of layers for quantization-aware training:ConvBn2d— Conv2d + BatchNormConvBnReLU2d— Conv2d + BatchNorm + ReLUConvReLU2d— Conv2d + ReLULinearReLU— Linear + ReLU
torch.nn.intrinsic.quantized— quantized version of fused layers for inference (no BatchNorm variants as it’s usually folded into convolution for inference):LinearReLU— Linear + ReLUConvReLU1d— 1D Convolution + ReLUConvReLU2d— 2D Convolution + ReLUConvReLU3d— 3D Convolution + ReLU
torch.nn.qat¶
Layers for the quantization-aware training
torch.quantization¶
Functions for eager mode quantization:
add_observer_()— Adds observer for the leaf modules (if quantization configuration is provided)add_quant_dequant()— Wraps the leaf child module usingQuantWrapperconvert()— Converts float module with observers into its quantized counterpart. Must have quantization configurationget_observer_dict()— Traverses the module children and collects all observers into adictprepare()— Prepares a copy of a model for quantizationprepare_qat()— Prepares a copy of a model for quantization aware trainingpropagate_qconfig_()— Propagates quantization configurations through the module hierarchy and assign them to each leaf modulequantize()— Function for eager mode post training static quantizationquantize_dynamic()— Function for eager mode post training dynamic quantizationquantize_qat()— Function for eager mode quantization aware training functionswap_module()— Swaps the module with its quantized counterpart (if quantizable and if it has an observer)default_eval_fn()— Default evaluation function used by thetorch.quantization.quantize()
Functions for graph mode quantization:
quantize_jit()- Function for graph mode post training static quantizationquantize_dynamic_jit()- Function for graph mode post training dynamic quantization
- Quantization configurations
QConfig— Quantization configuration classdefault_qconfig— Same asQConfig(activation=default_observer, weight=default_weight_observer)(SeeQConfig)default_qat_qconfig— Same asQConfig(activation=default_fake_quant, weight=default_weight_fake_quant)(SeeQConfig)default_dynamic_qconfig— Same asQConfigDynamic(weight=default_weight_observer)(SeeQConfigDynamic)float16_dynamic_qconfig— Same asQConfigDynamic(weight=NoopObserver.with_args(dtype=torch.float16))(SeeQConfigDynamic)
- Stubs
DeQuantStub- placeholder module for dequantize() operation in float-valued modelsQuantStub- placeholder module for quantize() operation in float-valued modelsQuantWrapper— wraps the module to be quantized. Inserts theQuantStuband
Observers for computing the quantization parameters
Default Observers. The rest of observers are available from
torch.quantization.observer:default_observer— Same asMinMaxObserver.with_args(reduce_range=True)default_weight_observer— Same asMinMaxObserver.with_args(dtype=torch.qint8, qscheme=torch.per_tensor_symmetric)
Observer— Abstract base class for observersMinMaxObserver— Derives the quantization parameters from the running minimum and maximum of the observed tensor inputs (per tensor variant)MovingAverageMinMaxObserver— Derives the quantization parameters from the running averages of the minimums and maximums of the observed tensor inputs (per tensor variant)PerChannelMinMaxObserver— Derives the quantization parameters from the running minimum and maximum of the observed tensor inputs (per channel variant)MovingAveragePerChannelMinMaxObserver— Derives the quantization parameters from the running averages of the minimums and maximums of the observed tensor inputs (per channel variant)HistogramObserver— Derives the quantization parameters by creating a histogram of running minimums and maximums.
- Observers that do not compute the quantization parameters:
RecordingObserver— Records all incoming tensors. Used for debugging only.NoopObserver— Pass-through observer. Used for situation when there are no quantization parameters (i.e. quantization tofloat16)
- FakeQuantize module
FakeQuantize— Module for simulating the quantization/dequantization at training time
torch.nn.quantized¶
Quantized version of standard NN layers.
Quantize— Quantization layer, used to automatically replaceQuantStubDeQuantize— Dequantization layer, used to replaceDeQuantStubFloatFunctional— Wrapper class to make stateless float operations stateful so that they can be replaced with quantized versionsQFunctional— Wrapper class for quantized versions of stateless operations liketorch.addConv1d— 1D convolutionConv2d— 2D convolutionConv3d— 3D convolutionLinear— Linear (fully-connected) layerMaxPool2d— 2D max poolingReLU— Rectified linear unitReLU6— Rectified linear unit with cut-off at quantized representation of 6ELU— ELUHardswish— HardswishBatchNorm2d— BatchNorm2d. Note: this module is usually fused with Conv or Linear. Performance on ARM is not optimized.BatchNorm3d— BatchNorm3d. Note: this module is usually fused with Conv or Linear. Performance on ARM is not optimized.LayerNorm— LayerNorm. Note: performance on ARM is not optimized.GroupNorm— GroupNorm. Note: performance on ARM is not optimized.InstanceNorm1d— InstanceNorm1d. Note: performance on ARM is not optimized.InstanceNorm2d— InstanceNorm2d. Note: performance on ARM is not optimized.InstanceNorm3d— InstanceNorm3d. Note: performance on ARM is not optimized.
torch.nn.quantized.dynamic¶
Layers used in dynamically quantized models (i.e. quantized only on weights)
torch.nn.quantized.functional¶
Functional versions of quantized NN layers (many of them accept explicit quantization output parameters)
adaptive_avg_pool2d()— 2D adaptive average poolingavg_pool2d()— 2D average poolingavg_pool3d()— 3D average poolingconv1d()— 1D convolutionconv2d()— 2D convolutionconv3d()— 3D convolutioninterpolate()— Down-/up- samplerlinear()— Linear (fully-connected) opmax_pool2d()— 2D max poolingrelu()— Rectified linear unitelu()— ELUhardsigmoid()— Hardsigmoidhardswish()— Hardswishhardtanh()— Hardtanhupsample()— Upsampler. Will be deprecated in favor ofinterpolate()upsample_bilinear()— Bilinear upsampler. Will be deprecated in favor ofupsample_nearest()— Nearest neighbor upsampler. Will be deprecated in favor of
Quantized dtypes and quantization schemes¶
torch.qscheme— Type to describe the quantization scheme of a tensor. Supported types:torch.per_tensor_affine— per tensor, asymmetrictorch.per_channel_affine— per channel, asymmetrictorch.per_tensor_symmetric— per tensor, symmetrictorch.per_channel_symmetric— per tensor, symmetric
torch.dtype— Type to describe the data. Supported types:torch.quint8— 8-bit unsigned integertorch.qint8— 8-bit signed integertorch.qint32— 32-bit signed integer
Quantization Workflows¶
PyTorch provides three approaches to quantize models.
Post Training Dynamic Quantization: This is the simplest to apply form of quantization where the weights are quantized ahead of time but the activations are dynamically quantized during inference. This is used for situations where the model execution time is dominated by loading weights from memory rather than computing the matrix multiplications. This is true for for LSTM and Transformer type models with small batch size. Applying dynamic quantization to a whole model can be done with a single call to
torch.quantization.quantize_dynamic(). See the quantization tutorialsPost Training Static Quantization: This is the most commonly used form of quantization where the weights are quantized ahead of time and the scale factor and bias for the activation tensors is pre-computed based on observing the behavior of the model during a calibration process. Post Training Quantization is typically when both memory bandwidth and compute savings are important with CNNs being a typical use case. The general process for doing post training quantization is:
Prepare the model:
Specify where the activations are quantized and dequantized explicitly by adding QuantStub and DeQuantStub modules.
Ensure that modules are not reused.
Convert any operations that require requantization into modules
Fuse operations like conv + relu or conv+batchnorm + relu together to improve both model accuracy and performance.
Specify the configuration of the quantization methods ‘97 such as selecting symmetric or asymmetric quantization and MinMax or L2Norm calibration techniques.
Use the
torch.quantization.prepare()to insert modules that will observe activation tensors during calibrationCalibrate the model by running inference against a calibration dataset
Finally, convert the model itself with the torch.quantization.convert() method. This does several things: it quantizes the weights, computes and stores the scale and bias value to be used each activation tensor, and replaces key operators quantized implementations.
See the quantization tutorials
Quantization Aware Training: In the rare cases where post training quantization does not provide adequate accuracy training can be done with simulated quantization using the
torch.quantization.FakeQuantize. Computations will take place in FP32 but with values clamped and rounded to simulate the effects of INT8 quantization. The sequence of steps is very similar.Steps (1) and (2) are identical.
Specify the configuration of the fake quantization methods ‘97 such as selecting symmetric or asymmetric quantization and MinMax or Moving Average or L2Norm calibration techniques.
Use the
torch.quantization.prepare_qat()to insert modules that will simulate quantization during training.Train or fine tune the model.
Identical to step (6) for post training quantization
See the quantization tutorials
While default implementations of observers to select the scale factor and bias based on observed tensor data are provided, developers can provide their own quantization functions. Quantization can be applied selectively to different parts of the model or configured differently for different parts of the model.
We also provide support for per channel quantization for conv2d(), conv3d() and linear()
Quantization workflows work by adding (e.g. adding observers as
.observer submodule) or replacing (e.g. converting nn.Conv2d to
nn.quantized.Conv2d) submodules in the model’s module hierarchy. It
means that the model stays a regular nn.Module-based instance throughout the
process and thus can work with the rest of PyTorch APIs.
Model Preparation for Quantization¶
It is necessary to currently make some modifications to the model definition prior to quantization. This is because currently quantization works on a module by module basis. Specifically, for all quantization techniques, the user needs to:
Convert any operations that require output requantization (and thus have additional parameters) from functionals to module form.
Specify which parts of the model need to be quantized either by assigning
`.qconfigattributes on submodules or by specifyingqconfig_dict
For static quantization techniques which quantize activations, the user needs to do the following in addition:
Specify where activations are quantized and de-quantized. This is done using
QuantStubandDeQuantStubmodules.Use
torch.nn.quantized.FloatFunctionalto wrap tensor operations that require special handling for quantization into modules. Examples are operations likeaddandcatwhich require special handling to determine output quantization parameters.Fuse modules: combine operations/modules into a single module to obtain higher accuracy and performance. This is done using the
torch.quantization.fuse_modules()API, which takes in lists of modules to be fused. We currently support the following fusions: [Conv, Relu], [Conv, BatchNorm], [Conv, BatchNorm, Relu], [Linear, Relu]
torch.quantization¶
This module implements the functions you call
directly to convert your model from FP32 to quantized form. For
example the prepare() is used in post training
quantization to prepares your model for the calibration step and
convert() actually converts the weights to int8 and
replaces the operations with their quantized counterparts. There are
other helper functions for things like quantizing the input to your
model and performing critical fusions like conv+relu.
Top-level quantization APIs¶
-
torch.quantization.quantize(model, run_fn, run_args, mapping=None, inplace=False)[source]¶ Quantize the input float model with post training static quantization.
First it will prepare the model for calibration, then it calls run_fn which will run the calibration step, after that we will convert the model to a quantized model.
- Parameters
model – input float model
run_fn – a calibration function for calibrating the prepared model
run_args – positional arguments for run_fn
inplace – carry out model transformations in-place, the original module is mutated
mapping – correspondence between original module types and quantized counterparts
- Returns
Quantized model.
-
torch.quantization.quantize_dynamic(model, qconfig_spec=None, dtype=torch.qint8, mapping=None, inplace=False)[source]¶ Converts a float model to dynamic (i.e. weights-only) quantized model.
Replaces specified modules with dynamic weight-only quantized versions and output the quantized model.
For simplest usage provide dtype argument that can be float16 or qint8. Weight-only quantization by default is performed for layers with large weights size - i.e. Linear and RNN variants.
Fine grained control is possible with qconfig and mapping that act similarly to quantize(). If qconfig is provided, the dtype argument is ignored.
- Parameters
module – input model
qconfig_spec –
Either:
A dictionary that maps from name or type of submodule to quantization configuration, qconfig applies to all submodules of a given module unless qconfig for the submodules are specified (when the submodule already has qconfig attribute). Entries in the dictionary need to be QConfigDynamic instances.
A set of types and/or submodule names to apply dynamic quantization to, in which case the dtype argument is used to specify the bit-width
inplace – carry out model transformations in-place, the original module is mutated
mapping – maps type of a submodule to a type of corresponding dynamically quantized version with which the submodule needs to be replaced
-
torch.quantization.quantize_qat(model, run_fn, run_args, inplace=False)[source]¶ Do quantization aware training and output a quantized model
- Parameters
model – input model
run_fn – a function for evaluating the prepared model, can be a function that simply runs the prepared model or a training loop
run_args – positional arguments for run_fn
- Returns
Quantized model.
-
torch.quantization.prepare(model, inplace=False, white_list={<class 'torch.nn.intrinsic.modules.fused.ConvReLU2d'>, <class 'torch.nn.modules.instancenorm.InstanceNorm2d'>, <class 'torch.nn.modules.batchnorm.BatchNorm2d'>, <class 'torch.nn.modules.normalization.GroupNorm'>, <class 'torch.nn.modules.rnn.LSTMCell'>, <class 'torch.nn.qat.modules.linear.Linear'>, <class 'torch.nn.modules.instancenorm.InstanceNorm3d'>, <class 'torch.nn.intrinsic.modules.fused.BNReLU2d'>, <class 'torch.nn.intrinsic.qat.modules.conv_fused.ConvBn2d'>, <class 'torch.nn.intrinsic.qat.modules.linear_relu.LinearReLU'>, <class 'torch.nn.modules.linear.Linear'>, <class 'torch.nn.intrinsic.qat.modules.conv_fused.ConvReLU2d'>, <class 'torch.nn.modules.conv.Conv1d'>, <class 'torch.nn.modules.normalization.LayerNorm'>, <class 'torch.nn.quantized.modules.functional_modules.FloatFunctional'>, <class 'torch.nn.modules.activation.ReLU6'>, <class 'torch.nn.modules.activation.Hardswish'>, <class 'torch.nn.modules.rnn.LSTM'>, <class 'torch.nn.intrinsic.modules.fused.ConvReLU3d'>, <class 'torch.nn.qat.modules.conv.Conv2d'>, <class 'torch.nn.modules.rnn.RNNCell'>, <class 'torch.nn.intrinsic.qat.modules.conv_fused.ConvBnReLU2d'>, <class 'torch.nn.intrinsic.modules.fused.ConvReLU1d'>, <class 'torch.nn.modules.conv.Conv3d'>, <class 'torch.nn.modules.batchnorm.BatchNorm3d'>, <class 'torch.nn.intrinsic.modules.fused.BNReLU3d'>, <class 'torch.nn.modules.rnn.GRUCell'>, <class 'torch.nn.intrinsic.modules.fused.ConvBnReLU2d'>, <class 'torch.quantization.stubs.QuantStub'>, <class 'torch.nn.modules.conv.Conv2d'>, <class 'torch.nn.intrinsic.modules.fused.ConvBn2d'>, <class 'torch.nn.modules.activation.ELU'>, <class 'torch.nn.intrinsic.modules.fused.LinearReLU'>, <class 'torch.nn.modules.container.Sequential'>, <class 'torch.nn.modules.instancenorm.InstanceNorm1d'>, <class 'torch.nn.modules.activation.ReLU'>}, observer_non_leaf_module_list=None)[source]¶ Prepares a copy of the model for quantization calibration or quantization-aware training.
Quantization configuration should be assigned preemptively to individual submodules in .qconfig attribute.
The model will be attached with observer or fake quant modules, and qconfig will be propagated.
- Parameters
model – input model to be modified in-place
inplace – carry out model transformations in-place, the original module is mutated
white_list – list of quantizable modules
observer_non_leaf_module_list – list of non-leaf modules we want to add observer
-
torch.quantization.prepare_qat(model, mapping=None, inplace=False)[source]¶ Prepares a copy of the model for quantization calibration or quantization-aware training and converts it to quantized version.
Quantization configuration should be assigned preemptively to individual submodules in .qconfig attribute.
- Parameters
model – input model to be modified in-place
mapping – dictionary that maps float modules to quantized modules to be replaced.
inplace – carry out model transformations in-place, the original module is mutated
-
torch.quantization.convert(module, mapping=None, inplace=False)[source]¶ Converts the float module with observers (where we can get quantization parameters) to a quantized module.
- Parameters
module – calibrated module with observers
mapping – a dictionary that maps from float module type to quantized module type, can be overwritten to allow swapping user defined Modules
inplace – carry out model transformations in-place, the original module is mutated
-
class
torch.quantization.QConfig[source]¶ Describes how to quantize a layer or a part of the network by providing settings (observer classes) for activations and weights respectively.
Note that QConfig needs to contain observer classes (like MinMaxObserver) or a callable that returns instances on invocation, not the concrete observer instances themselves. Quantization preparation function will instantiate observers multiple times for each of the layers.
Observer classes have usually reasonable default arguments, but they can be overwritten with with_args method (that behaves like functools.partial):
my_qconfig = QConfig(activation=MinMaxObserver.with_args(dtype=torch.qint8), weight=default_observer.with_args(dtype=torch.qint8))
-
class
torch.quantization.QConfigDynamic[source]¶ Describes how to dynamically quantize a layer or a part of the network by providing settings (observer classes) for weights.
It’s like QConfig, but for dynamic quantization.
Note that QConfigDynamic needs to contain observer classes (like MinMaxObserver) or a callable that returns instances on invocation, not the concrete observer instances themselves. Quantization function will instantiate observers multiple times for each of the layers.
Observer classes have usually reasonable default arguments, but they can be overwritten with with_args method (that behaves like functools.partial):
my_qconfig = QConfigDynamic(weight=default_observer.with_args(dtype=torch.qint8))
Preparing model for quantization¶
-
torch.quantization.fuse_modules(model, modules_to_fuse, inplace=False, fuser_func=<function fuse_known_modules>)[source]¶ Fuses a list of modules into a single module
Fuses only the following sequence of modules: conv, bn conv, bn, relu conv, relu linear, relu bn, relu All other sequences are left unchanged. For these sequences, replaces the first item in the list with the fused module, replacing the rest of the modules with identity.
- Parameters
model – Model containing the modules to be fused
modules_to_fuse – list of list of module names to fuse. Can also be a list of strings if there is only a single list of modules to fuse.
inplace – bool specifying if fusion happens in place on the model, by default a new model is returned
fuser_func – Function that takes in a list of modules and outputs a list of fused modules of the same length. For example, fuser_func([convModule, BNModule]) returns the list [ConvBNModule, nn.Identity()] Defaults to torch.quantization.fuse_known_modules
- Returns
model with fused modules. A new copy is created if inplace=True.
Examples:
>>> m = myModel() >>> # m is a module containing the sub-modules below >>> modules_to_fuse = [ ['conv1', 'bn1', 'relu1'], ['submodule.conv', 'submodule.relu']] >>> fused_m = torch.quantization.fuse_modules(m, modules_to_fuse) >>> output = fused_m(input) >>> m = myModel() >>> # Alternately provide a single list of modules to fuse >>> modules_to_fuse = ['conv1', 'bn1', 'relu1'] >>> fused_m = torch.quantization.fuse_modules(m, modules_to_fuse) >>> output = fused_m(input)
-
class
torch.quantization.QuantStub(qconfig=None)[source]¶ Quantize stub module, before calibration, this is same as an observer, it will be swapped as nnq.Quantize in convert.
- Parameters
qconfig – quantization configuration for the tensor, if qconfig is not provided, we will get qconfig from parent modules
-
class
torch.quantization.DeQuantStub[source]¶ Dequantize stub module, before calibration, this is same as identity, this will be swapped as nnq.DeQuantize in convert.
-
class
torch.quantization.QuantWrapper(module)[source]¶ A wrapper class that wraps the input module, adds QuantStub and DeQuantStub and surround the call to module with call to quant and dequant modules.
This is used by the quantization utility functions to add the quant and dequant modules, before convert function QuantStub will just be observer, it observes the input tensor, after convert, QuantStub will be swapped to nnq.Quantize which does actual quantization. Similarly for DeQuantStub.
-
torch.quantization.add_quant_dequant(module)[source]¶ Wrap the leaf child module in QuantWrapper if it has a valid qconfig Note that this function will modify the children of module inplace and it can return a new module which wraps the input module as well.
- Parameters
module – input module with qconfig attributes for all the leaf modules
we want to quantize (that) –
- Returns
Either the inplace modified module with submodules wrapped in QuantWrapper based on qconfig or a new QuantWrapper module which wraps the input module, the latter case only happens when the input module is a leaf module and we want to quantize it.
Utility functions¶
-
torch.quantization.add_observer_(module, non_leaf_module_list=None, device=None)[source]¶ Add observer for the leaf child of the module.
This function insert observer module to all leaf child module that has a valid qconfig attribute.
- Parameters
module – input module with qconfig attributes for all the leaf modules that we want to quantize
device – parent device, if any
non_leaf_module_list – list of non-leaf modules we want to add observer
- Returns
None, module is modified inplace with added observer modules and forward_hooks
-
torch.quantization.swap_module(mod, mapping)[source]¶ Swaps the module if it has a quantized counterpart and it has an observer attached.
- Parameters
mod – input module
mapping – a dictionary that maps from nn module to nnq module
- Returns
The corresponding quantized module of mod
-
torch.quantization.propagate_qconfig_(module, qconfig_dict=None, white_list=None)[source]¶ Propagate qconfig through the module hierarchy and assign qconfig attribute on each leaf module
- Parameters
module – input module
qconfig_dict – dictionary that maps from name or type of submodule to quantization configuration, qconfig applies to all submodules of a given module unless qconfig for the submodules are specified (when the submodule already has qconfig attribute)
- Returns
None, module is modified inplace with qconfig attached
Observers¶
-
class
torch.quantization.ObserverBase(dtype)[source]¶ Base observer Module. Any observer implementation should derive from this class.
Concrete observers should follow the same API. In forward, they will update the statistics of the observed Tensor. And they should provide a calculate_qparams function that computes the quantization parameters given the collected statistics.
- Parameters
dtype – Quantized data type
-
classmethod
with_args(**kwargs)¶ Wrapper that allows creation of class factories.
This can be useful when there is a need to create classes with the same constructor arguments, but different instances.
Example:
>>> Foo.with_args = classmethod(_with_args) >>> foo_builder = Foo.with_args(a=3, b=4).with_args(answer=42) >>> foo_instance1 = foo_builder() >>> foo_instance2 = foo_builder() >>> id(foo_instance1) == id(foo_instance2) False
-
class
torch.quantization.MinMaxObserver(dtype=torch.quint8, qscheme=torch.per_tensor_affine, reduce_range=False)[source]¶ Observer module for computing the quantization parameters based on the running min and max values.
This observer uses the tensor min/max statistics to compute the quantization parameters. The module records the running minimum and maximum of incoming tensors, and uses this statistic to compute the quantization parameters.
- Parameters
dtype – Quantized data type
qscheme – Quantization scheme to be used
reduce_range – Reduces the range of the quantized data type by 1 bit
Given running min/max as and , scale and zero point are computed as:
The running minimum/maximum is computed as:
where is the observed tensor.
The scale and zero point are then computed as:
where and are the minimum and maximum of the quantized data type.
Warning
Only works with
torch.per_tensor_symmetricquantization schemeWarning
dtypecan only taketorch.qint8ortorch.quint8.Note
If the running minimum equals to the running maximum, the scale and zero_point are set to 1.0 and 0.
-
class
torch.quantization.MovingAverageMinMaxObserver(averaging_constant=0.01, dtype=torch.quint8, qscheme=torch.per_tensor_affine, reduce_range=False)[source]¶ Observer module for computing the quantization parameters based on the moving average of the min and max values.
This observer computes the quantization parameters based on the moving averages of minimums and maximums of the incoming tensors. The module records the average minimum and maximum of incoming tensors, and uses this statistic to compute the quantization parameters.
- Parameters
averaging_constant – Averaging constant for min/max.
dtype – Quantized data type
qscheme – Quantization scheme to be used
reduce_range – Reduces the range of the quantized data type by 1 bit
The moving average min/max is computed as follows
where is the running average min/max, is is the incoming tensor, and is the
averaging_constant.The scale and zero point are then computed as in
MinMaxObserver.Note
Only works with
torch.per_tensor_affinequantization scheme.Note
If the running minimum equals to the running maximum, the scale and zero_point are set to 1.0 and 0.
-
class
torch.quantization.PerChannelMinMaxObserver(ch_axis=0, dtype=torch.quint8, qscheme=torch.per_channel_affine, reduce_range=False)[source]¶ Observer module for computing the quantization parameters based on the running per channel min and max values.
This observer uses the tensor min/max statistics to compute the per channel quantization parameters. The module records the running minimum and maximum of incoming tensors, and uses this statistic to compute the quantization parameters.
- Parameters
ch_axis – Channel axis
dtype – Quantized data type
qscheme – Quantization scheme to be used
reduce_range – Reduces the range of the quantized data type by 1 bit
The quantization parameters are computed the same way as in
MinMaxObserver, with the difference that the running min/max values are stored per channel. Scales and zero points are thus computed per channel as well.Note
If the running minimum equals to the running maximum, the scales and zero_points are set to 1.0 and 0.
-
class
torch.quantization.MovingAveragePerChannelMinMaxObserver(averaging_constant=0.01, ch_axis=0, dtype=torch.quint8, qscheme=torch.per_channel_affine, reduce_range=False)[source]¶ Observer module for computing the quantization parameters based on the running per channel min and max values.
This observer uses the tensor min/max statistics to compute the per channel quantization parameters. The module records the running minimum and maximum of incoming tensors, and uses this statistic to compute the quantization parameters.
- Parameters
averaging_constant – Averaging constant for min/max.
ch_axis – Channel axis
dtype – Quantized data type
qscheme – Quantization scheme to be used
reduce_range – Reduces the range of the quantized data type by 1 bit
The quantization parameters are computed the same way as in
MovingAverageMinMaxObserver, with the difference that the running min/max values are stored per channel. Scales and zero points are thus computed per channel as well.Note
If the running minimum equals to the running maximum, the scales and zero_points are set to 1.0 and 0.
-
class
torch.quantization.HistogramObserver(bins=2048, upsample_rate=128, dtype=torch.quint8, qscheme=torch.per_tensor_affine, reduce_range=False)[source]¶ The module records the running histogram of tensor values along with min/max values.
calculate_qparamswill calculate scale and zero_point.- Parameters
bins – Number of bins to use for the histogram
upsample_rate – Factor by which the histograms are upsampled, this is used to interpolate histograms with varying ranges across observations
dtype – Quantized data type
qscheme – Quantization scheme to be used
reduce_range – Reduces the range of the quantized data type by 1 bit
The scale and zero point are computed as follows:
- Create the histogram of the incoming inputs.
The histogram is computed continuously, and the ranges per bin change with every new tensor observed.
- Search the distribution in the histogram for optimal min/max values.
The search for the min/max values ensures the minimization of the quantization error with respect to the floating point model.
- Compute the scale and zero point the same way as in the
-
class
torch.quantization.FakeQuantize(observer=<class 'torch.quantization.observer.MovingAverageMinMaxObserver'>, quant_min=0, quant_max=255, **observer_kwargs)[source]¶ Simulate the quantize and dequantize operations in training time. The output of this module is given by
x_out = (clamp(round(x/scale + zero_point), quant_min, quant_max)-zero_point)*scale
scaledefines the scale factor used for quantization.zero_pointspecifies the quantized value to which 0 in floating point maps toquant_minspecifies the minimum allowable quantized value.quant_maxspecifies the maximum allowable quantized value.fake_quant_enablecontrols the application of fake quantization on tensors, note that statistics can still be updated.observer_enablecontrols statistics collection on tensorsdtypespecifies the quantized dtype that is being emulated with fake-quantization,allowable values are torch.qint8 and torch.quint8. The values of quant_min and quant_max should be chosen to be consistent with the dtype
- Parameters
- Variables
~FakeQuantize.observer (Module) – User provided module that collects statistics on the input tensor and provides a method to calculate scale and zero-point.
-
class
torch.quantization.NoopObserver(dtype=torch.float16)[source]¶ Observer that doesn’t do anything and just passes its configuration to the quantized module’s
.from_float().Primarily used for quantization to float16 which doesn’t require determining ranges.
- Parameters
dtype – Quantized data type
Debugging utilities¶
-
torch.quantization.get_observer_dict(mod, target_dict, prefix='')[source]¶ Traverse the modules and save all observers into dict. This is mainly used for quantization accuracy debug :param mod: the top module we want to save all observers :param prefix: the prefix for the current module :param target_dict: the dictionary used to save all the observers
torch.nn.intrinsic¶
This module implements the combined (fused) modules conv + relu which can be then quantized.
ConvBn1d¶
ConvBn2d¶
ConvBnReLU1d¶
ConvBnReLU2d¶
ConvReLU1d¶
ConvReLU2d¶
ConvReLU3d¶
torch.nn.intrinsic.qat¶
This module implements the versions of those fused operations needed for quantization aware training.
ConvBn2d¶
-
class
torch.nn.intrinsic.qat.ConvBn2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=None, padding_mode='zeros', eps=1e-05, momentum=0.1, freeze_bn=False, qconfig=None)[source]¶ A ConvBn2d module is a module fused from Conv2d and BatchNorm2d, attached with FakeQuantize modules for both output activation and weight, used in quantization aware training.
We combined the interface of
torch.nn.Conv2dandtorch.nn.BatchNorm2d.Implementation details: https://arxiv.org/pdf/1806.08342.pdf section 3.2.2
Similar to
torch.nn.Conv2d, with FakeQuantize modules initialized to default.- Variables
~ConvBn2d.freeze_bn –
~ConvBn2d.activation_post_process – fake quant module for output activation
~ConvBn2d.weight_fake_quant – fake quant module for weight
ConvBnReLU2d¶
-
class
torch.nn.intrinsic.qat.ConvBnReLU2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=None, padding_mode='zeros', eps=1e-05, momentum=0.1, freeze_bn=False, qconfig=None)[source]¶ A ConvBnReLU2d module is a module fused from Conv2d, BatchNorm2d and ReLU, attached with FakeQuantize modules for both output activation and weight, used in quantization aware training.
We combined the interface of
torch.nn.Conv2dandtorch.nn.BatchNorm2dandtorch.nn.ReLU.Implementation details: https://arxiv.org/pdf/1806.08342.pdf
Similar to torch.nn.Conv2d, with FakeQuantize modules initialized to default.
- Variables
~ConvBnReLU2d.observer – fake quant module for output activation, it’s called observer to align with post training flow
~ConvBnReLU2d.weight_fake_quant – fake quant module for weight
ConvReLU2d¶
-
class
torch.nn.intrinsic.qat.ConvReLU2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', qconfig=None)[source]¶ A ConvReLU2d module is a fused module of Conv2d and ReLU, attached with FakeQuantize modules for both output activation and weight for quantization aware training.
We combined the interface of
Conv2dandBatchNorm2d.- Variables
~ConvReLU2d.activation_post_process – fake quant module for output activation
~ConvReLU2d.weight_fake_quant – fake quant module for weight
LinearReLU¶
-
class
torch.nn.intrinsic.qat.LinearReLU(in_features, out_features, bias=True, qconfig=None)[source]¶ A LinearReLU module fused from Linear and ReLU modules, attached with FakeQuantize modules for output activation and weight, used in quantization aware training.
We adopt the same interface as
torch.nn.Linear.Similar to torch.nn.intrinsic.LinearReLU, with FakeQuantize modules initialized to default.
- Variables
~LinearReLU.activation_post_process – fake quant module for output activation
~LinearReLU.weight – fake quant module for weight
Examples:
>>> m = nn.qat.LinearReLU(20, 30) >>> input = torch.randn(128, 20) >>> output = m(input) >>> print(output.size()) torch.Size([128, 30])
torch.nn.intrinsic.quantized¶
This module implements the quantized implementations of fused operations like conv + relu.
ConvReLU2d¶
-
class
torch.nn.intrinsic.quantized.ConvReLU2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')[source]¶ A ConvReLU2d module is a fused module of Conv2d and ReLU
We adopt the same interface as
torch.nn.quantized.Conv2d.- Variables
as torch.nn.quantized.Conv2d (Same) –
ConvReLU3d¶
-
class
torch.nn.intrinsic.quantized.ConvReLU3d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')[source]¶ A ConvReLU3d module is a fused module of Conv3d and ReLU
We adopt the same interface as
torch.nn.quantized.Conv3d.Attributes: Same as torch.nn.quantized.Conv3d
LinearReLU¶
-
class
torch.nn.intrinsic.quantized.LinearReLU(in_features, out_features, bias=True, dtype=torch.qint8)[source]¶ A LinearReLU module fused from Linear and ReLU modules
We adopt the same interface as
torch.nn.quantized.Linear.- Variables
as torch.nn.quantized.Linear (Same) –
Examples:
>>> m = nn.intrinsic.LinearReLU(20, 30) >>> input = torch.randn(128, 20) >>> output = m(input) >>> print(output.size()) torch.Size([128, 30])
torch.nn.qat¶
This module implements versions of the key nn modules Conv2d() and Linear() which run in FP32 but with rounding applied to simulate the effect of INT8 quantization.
Conv2d¶
-
class
torch.nn.qat.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros', qconfig=None)[source]¶ A Conv2d module attached with FakeQuantize modules for both output activation and weight, used for quantization aware training.
We adopt the same interface as torch.nn.Conv2d, please see https://pytorch.org/docs/stable/nn.html?highlight=conv2d#torch.nn.Conv2d for documentation.
Similar to torch.nn.Conv2d, with FakeQuantize modules initialized to default.
- Variables
~Conv2d.activation_post_process – fake quant module for output activation
~Conv2d.weight_fake_quant – fake quant module for weight
Linear¶
-
class
torch.nn.qat.Linear(in_features, out_features, bias=True, qconfig=None)[source]¶ A linear module attached with FakeQuantize modules for both output activation and weight, used for quantization aware training.
We adopt the same interface as torch.nn.Linear, please see https://pytorch.org/docs/stable/nn.html#torch.nn.Linear for documentation.
Similar to torch.nn.Linear, with FakeQuantize modules initialized to default.
- Variables
~Linear.activation_post_process – fake quant module for output activation
~Linear.weight – fake quant module for weight
torch.nn.quantized¶
This module implements the quantized versions of the nn layers such as ~`torch.nn.Conv2d` and torch.nn.ReLU.
Functional interface¶
Functional interface (quantized).
-
torch.nn.quantized.functional.relu(input, inplace=False) → Tensor[source]¶ Applies the rectified linear unit function element-wise. See
ReLUfor more details.- Parameters
input – quantized input
inplace – perform the computation inplace
-
torch.nn.quantized.functional.linear(input: torch.Tensor, weight: torch.Tensor, bias: Optional[torch.Tensor] = None, scale: Optional[float] = None, zero_point: Optional[int] = None) → torch.Tensor[source]¶ Applies a linear transformation to the incoming quantized data: . See
LinearNote
Current implementation packs weights on every call, which has penalty on performance. If you want to avoid the overhead, use
Linear.- Parameters
input (Tensor) – Quantized input of type torch.quint8
weight (Tensor) – Quantized weight of type torch.qint8
bias (Tensor) – None or fp32 bias of type torch.float
scale (double) – output scale. If None, derived from the input scale
zero_point (long) – output zero point. If None, derived from the input zero_point
- Shape:
Input: where * means any number of additional dimensions
Weight:
Bias:
Output:
-
torch.nn.quantized.functional.conv1d(input, weight, bias, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', scale=1.0, zero_point=0, dtype=torch.quint8)[source]¶ Applies a 1D convolution over a quantized 1D input composed of several input planes.
See
Conv1dfor details and output shape.- Parameters
input – quantized input tensor of shape
weight – quantized filters of shape
bias – non-quantized bias tensor of shape . The tensor type must be torch.float.
stride – the stride of the convolving kernel. Can be a single number or a tuple (sW,). Default: 1
padding – implicit paddings on both sides of the input. Can be a single number or a tuple (padW,). Default: 0
dilation – the spacing between kernel elements. Can be a single number or a tuple (dW,). Default: 1
groups – split input into groups, should be divisible by the number of groups. Default: 1
padding_mode – the padding mode to use. Only “zeros” is supported for quantized convolution at the moment. Default: “zeros”
scale – quantization scale for the output. Default: 1.0
zero_point – quantization zero_point for the output. Default: 0
dtype – quantization data type to use. Default:
torch.quint8
Examples:
>>> from torch.nn.quantized import functional as qF >>> filters = torch.randn(33, 16, 3, dtype=torch.float) >>> inputs = torch.randn(20, 16, 50, dtype=torch.float) >>> bias = torch.randn(33, dtype=torch.float) >>> >>> scale, zero_point = 1.0, 0 >>> dtype_inputs = torch.quint8 >>> dtype_filters = torch.qint8 >>> >>> q_filters = torch.quantize_per_tensor(filters, scale, zero_point, dtype_filters) >>> q_inputs = torch.quantize_per_tensor(inputs, scale, zero_point, dtype_inputs) >>> qF.conv1d(q_inputs, q_filters, bias, padding=1, scale=scale, zero_point=zero_point)
-
torch.nn.quantized.functional.conv2d(input, weight, bias, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', scale=1.0, zero_point=0, dtype=torch.quint8)[source]¶ Applies a 2D convolution over a quantized 2D input composed of several input planes.
See
Conv2dfor details and output shape.- Parameters
input – quantized input tensor of shape
weight – quantized filters of shape
bias – non-quantized bias tensor of shape . The tensor type must be torch.float.
stride – the stride of the convolving kernel. Can be a single number or a tuple (sH, sW). Default: 1
padding – implicit paddings on both sides of the input. Can be a single number or a tuple (padH, padW). Default: 0
dilation – the spacing between kernel elements. Can be a single number or a tuple (dH, dW). Default: 1
groups – split input into groups, should be divisible by the number of groups. Default: 1
padding_mode – the padding mode to use. Only “zeros” is supported for quantized convolution at the moment. Default: “zeros”
scale – quantization scale for the output. Default: 1.0
zero_point – quantization zero_point for the output. Default: 0
dtype – quantization data type to use. Default:
torch.quint8
Examples:
>>> from torch.nn.quantized import functional as qF >>> filters = torch.randn(8, 4, 3, 3, dtype=torch.float) >>> inputs = torch.randn(1, 4, 5, 5, dtype=torch.float) >>> bias = torch.randn(8, dtype=torch.float) >>> >>> scale, zero_point = 1.0, 0 >>> dtype_inputs = torch.quint8 >>> dtype_filters = torch.qint8 >>> >>> q_filters = torch.quantize_per_tensor(filters, scale, zero_point, dtype_filters) >>> q_inputs = torch.quantize_per_tensor(inputs, scale, zero_point, dtype_inputs) >>> qF.conv2d(q_inputs, q_filters, bias, padding=1, scale=scale, zero_point=zero_point)
-
torch.nn.quantized.functional.conv3d(input, weight, bias, stride=1, padding=0, dilation=1, groups=1, padding_mode='zeros', scale=1.0, zero_point=0, dtype=torch.quint8)[source]¶ Applies a 3D convolution over a quantized 3D input composed of several input planes.
See
Conv3dfor details and output shape.- Parameters
input – quantized input tensor of shape
weight – quantized filters of shape
bias – non-quantized bias tensor of shape . The tensor type must be torch.float.
stride – the stride of the convolving kernel. Can be a single number or a tuple (sD, sH, sW). Default: 1
padding – implicit paddings on both sides of the input. Can be a single number or a tuple (padD, padH, padW). Default: 0
dilation – the spacing between kernel elements. Can be a single number or a tuple (dD, dH, dW). Default: 1
groups – split input into groups, should be divisible by the number of groups. Default: 1
padding_mode – the padding mode to use. Only “zeros” is supported for quantized convolution at the moment. Default: “zeros”
scale – quantization scale for the output. Default: 1.0
zero_point – quantization zero_point for the output. Default: 0
dtype – quantization data type to use. Default:
torch.quint8
Examples:
>>> from torch.nn.quantized import functional as qF >>> filters = torch.randn(8, 4, 3, 3, 3, dtype=torch.float) >>> inputs = torch.randn(1, 4, 5, 5, 5, dtype=torch.float) >>> bias = torch.randn(8, dtype=torch.float) >>> >>> scale, zero_point = 1.0, 0 >>> dtype_inputs = torch.quint8 >>> dtype_filters = torch.qint8 >>> >>> q_filters = torch.quantize_per_tensor(filters, scale, zero_point, dtype_filters) >>> q_inputs = torch.quantize_per_tensor(inputs, scale, zero_point, dtype_inputs) >>> qF.conv3d(q_inputs, q_filters, bias, padding=1, scale=scale, zero_point=zero_point)
-
torch.nn.quantized.functional.max_pool2d(input, kernel_size, stride=None, padding=0, dilation=1, ceil_mode=False, return_indices=False)[source]¶ Applies a 2D max pooling over a quantized input signal composed of several quantized input planes.
Note
The input quantization parameters are propagated to the output.
See
MaxPool2dfor details.
-
torch.nn.quantized.functional.adaptive_avg_pool2d(input: Tensor, output_size: BroadcastingList2[int]) → Tensor[source]¶ Applies a 2D adaptive average pooling over a quantized input signal composed of several quantized input planes.
Note
The input quantization parameters propagate to the output.
See
AdaptiveAvgPool2dfor details and output shape.- Parameters
output_size – the target output size (single integer or double-integer tuple)
-
torch.nn.quantized.functional.avg_pool2d(input, kernel_size, stride=None, padding=0, ceil_mode=False, count_include_pad=True, divisor_override=None)[source]¶ Applies 2D average-pooling operation in regions by step size steps. The number of output features is equal to the number of input planes.
Note
The input quantization parameters propagate to the output.
See
AvgPool2dfor details and output shape.- Parameters
input – quantized input tensor
kernel_size – size of the pooling region. Can be a single number or a tuple (kH, kW)
stride – stride of the pooling operation. Can be a single number or a tuple (sH, sW). Default:
kernel_sizepadding – implicit zero paddings on both sides of the input. Can be a single number or a tuple (padH, padW). Default: 0
ceil_mode – when True, will use ceil instead of floor in the formula to compute the output shape. Default:
Falsecount_include_pad – when True, will include the zero-padding in the averaging calculation. Default:
Truedivisor_override – if specified, it will be used as divisor, otherwise size of the pooling region will be used. Default: None
-
torch.nn.quantized.functional.interpolate(input, size=None, scale_factor=None, mode='nearest', align_corners=None)[source]¶ Down/up samples the input to either the given
sizeor the givenscale_factorSee
torch.nn.functional.interpolate()for implementation details.The input dimensions are interpreted in the form: mini-batch x channels x [optional depth] x [optional height] x width.
Note
The input quantization parameters propagate to the output.
Note
Only 2D/3D input is supported for quantized inputs
Note
Only the following modes are supported for the quantized inputs:
bilinear
nearest
- Parameters
input (Tensor) – the input tensor
size (int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int]) – output spatial size.
scale_factor (float or Tuple[float]) – multiplier for spatial size. Has to match input size if it is a tuple.
mode (str) – algorithm used for upsampling:
'nearest'|'bilinear'align_corners (bool, optional) – Geometrically, we consider the pixels of the input and output as squares rather than points. If set to
True, the input and output tensors are aligned by the center points of their corner pixels, preserving the values at the corner pixels. If set toFalse, the input and output tensors are aligned by the corner points of their corner pixels, and the interpolation uses edge value padding for out-of-boundary values, making this operation independent of input size whenscale_factoris kept the same. This only has an effect whenmodeis'bilinear'. Default:False
-
torch.nn.quantized.functional.hardswish(input: torch.Tensor, scale: float, zero_point: int) → torch.Tensor[source]¶ This is the quantized version of
hardswish().- Parameters
input – quantized input
scale – quantization scale of the output tensor
zero_point – quantization zero point of the output tensor
-
torch.nn.quantized.functional.upsample(input, size=None, scale_factor=None, mode='nearest', align_corners=None)[source]¶ Upsamples the input to either the given
sizeor the givenscale_factorWarning
This function is deprecated in favor of
torch.nn.quantized.functional.interpolate(). This is equivalent withnn.quantized.functional.interpolate(...).See
torch.nn.functional.interpolate()for implementation details.The input dimensions are interpreted in the form: mini-batch x channels x [optional depth] x [optional height] x width.
Note
The input quantization parameters propagate to the output.
Note
Only 2D input is supported for quantized inputs
Note
Only the following modes are supported for the quantized inputs:
bilinear
nearest
- Parameters
input (Tensor) – quantized input tensor
size (int or Tuple[int] or Tuple[int, int] or Tuple[int, int, int]) – output spatial size.
scale_factor (float or Tuple[float]) – multiplier for spatial size. Has to be an integer.
mode (string) – algorithm used for upsampling:
'nearest'|'bilinear'align_corners (bool, optional) – Geometrically, we consider the pixels of the input and output as squares rather than points. If set to
True, the input and output tensors are aligned by the center points of their corner pixels, preserving the values at the corner pixels. If set toFalse, the input and output tensors are aligned by the corner points of their corner pixels, and the interpolation uses edge value padding for out-of-boundary values, making this operation independent of input size whenscale_factoris kept the same. This only has an effect whenmodeis'bilinear'. Default:False
Warning
With
align_corners = True, the linearly interpolating modes (bilinear) don’t proportionally align the output and input pixels, and thus the output values can depend on the input size. This was the default behavior for these modes up to version 0.3.1. Since then, the default behavior isalign_corners = False. SeeUpsamplefor concrete examples on how this affects the outputs.
-
torch.nn.quantized.functional.upsample_bilinear(input, size=None, scale_factor=None)[source]¶ Upsamples the input, using bilinear upsampling.
Warning
This function is deprecated in favor of
torch.nn.quantized.functional.interpolate(). This is equivalent withnn.quantized.functional.interpolate(..., mode='bilinear', align_corners=True).Note
The input quantization parameters propagate to the output.
Note
Only 2D inputs are supported
-
torch.nn.quantized.functional.upsample_nearest(input, size=None, scale_factor=None)[source]¶ Upsamples the input, using nearest neighbours’ pixel values.
Warning
This function is deprecated in favor of
torch.nn.quantized.functional.interpolate(). This is equivalent withnn.quantized.functional.interpolate(..., mode='nearest').Note
The input quantization parameters propagate to the output.
Note
Only 2D inputs are supported
ReLU¶
-
class
torch.nn.quantized.ReLU(inplace=False)[source]¶ Applies quantized rectified linear unit function element-wise:
, where is the zero point.
Please see https://pytorch.org/docs/stable/nn.html#torch.nn.ReLU for more documentation on ReLU.
- Parameters
inplace – (Currently not supported) can optionally do the operation in-place.
- Shape:
Input: where * means, any number of additional dimensions
Output: , same shape as the input
Examples:
>>> m = nn.quantized.ReLU() >>> input = torch.randn(2) >>> input = torch.quantize_per_tensor(input, 1.0, 0, dtype=torch.qint32) >>> output = m(input)
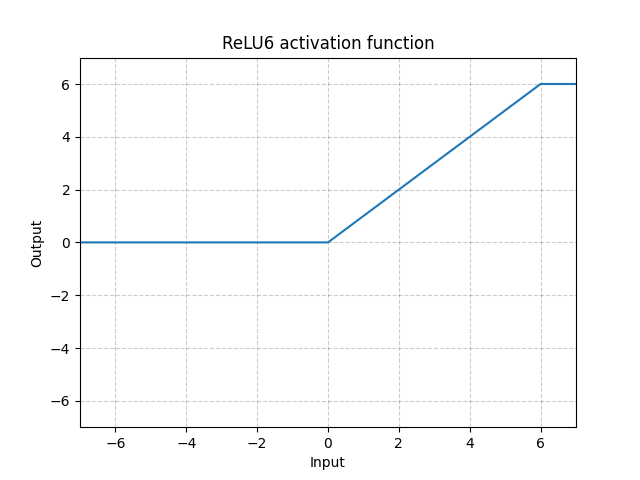
ReLU6¶
-
class
torch.nn.quantized.ReLU6(inplace=False)[source]¶ Applies the element-wise function:
, where is the zero_point, and is the quantized representation of number 6.
- Parameters
inplace – can optionally do the operation in-place. Default:
False
- Shape:
Input: where * means, any number of additional dimensions
Output: , same shape as the input
Examples:
>>> m = nn.quantized.ReLU6() >>> input = torch.randn(2) >>> input = torch.quantize_per_tensor(input, 1.0, 0, dtype=torch.qint32) >>> output = m(input)
ELU¶
Hardswish¶
Conv1d¶
-
class
torch.nn.quantized.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')[source]¶ Applies a 1D convolution over a quantized input signal composed of several quantized input planes.
For details on input arguments, parameters, and implementation see
Conv1d.Note
Only zeros is supported for the
padding_modeargument.Note
Only torch.quint8 is supported for the input data type.
- Variables
See
Conv1dfor other attributes.Examples:
>>> m = nn.quantized.Conv1d(16, 33, 3, stride=2) >>> input = torch.randn(20, 16, 100) >>> # quantize input to quint8 >>> q_input = torch.quantize_per_tensor(input, scale=1.0, zero_point=0, dtype=torch.quint8) >>> output = m(q_input)
Conv2d¶
-
class
torch.nn.quantized.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')[source]¶ Applies a 2D convolution over a quantized input signal composed of several quantized input planes.
For details on input arguments, parameters, and implementation see
Conv2d.Note
Only zeros is supported for the
padding_modeargument.Note
Only torch.quint8 is supported for the input data type.
- Variables
See
Conv2dfor other attributes.Examples:
>>> # With square kernels and equal stride >>> m = nn.quantized.Conv2d(16, 33, 3, stride=2) >>> # non-square kernels and unequal stride and with padding >>> m = nn.quantized.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2)) >>> # non-square kernels and unequal stride and with padding and dilation >>> m = nn.quantized.Conv2d(16, 33, (3, 5), stride=(2, 1), padding=(4, 2), dilation=(3, 1)) >>> input = torch.randn(20, 16, 50, 100) >>> # quantize input to quint8 >>> q_input = torch.quantize_per_tensor(input, scale=1.0, zero_point=0, dtype=torch.quint8) >>> output = m(q_input)
Conv3d¶
-
class
torch.nn.quantized.Conv3d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')[source]¶ Applies a 3D convolution over a quantized input signal composed of several quantized input planes.
For details on input arguments, parameters, and implementation see
Conv3d.Note
Only zeros is supported for the
padding_modeargument.Note
Only torch.quint8 is supported for the input data type.
- Variables
See
Conv3dfor other attributes.Examples:
>>> # With square kernels and equal stride >>> m = nn.quantized.Conv3d(16, 33, 3, stride=2) >>> # non-square kernels and unequal stride and with padding >>> m = nn.quantized.Conv3d(16, 33, (3, 5, 5), stride=(1, 2, 2), padding=(1, 2, 2)) >>> # non-square kernels and unequal stride and with padding and dilation >>> m = nn.quantized.Conv3d(16, 33, (3, 5, 5), stride=(1, 2, 2), padding=(1, 2, 2), dilation=(1, 2, 2)) >>> input = torch.randn(20, 16, 56, 56, 56) >>> # quantize input to quint8 >>> q_input = torch.quantize_per_tensor(input, scale=1.0, zero_point=0, dtype=torch.quint8) >>> output = m(q_input)
FloatFunctional¶
-
class
torch.nn.quantized.FloatFunctional[source]¶ State collector class for float operations.
The instance of this class can be used instead of the
torch.prefix for some operations. See example usage below.Note
This class does not provide a
forwardhook. Instead, you must use one of the underlying functions (e.g.add).Examples:
>>> f_add = FloatFunctional() >>> a = torch.tensor(3.0) >>> b = torch.tensor(4.0) >>> f_add.add(a, b) # Equivalent to ``torch.add(a, b)``
- Valid operation names:
add
cat
mul
add_relu
add_scalar
mul_scalar
QFunctional¶
-
class
torch.nn.quantized.QFunctional[source]¶ Wrapper class for quantized operations.
The instance of this class can be used instead of the
torch.ops.quantizedprefix. See example usage below.Note
This class does not provide a
forwardhook. Instead, you must use one of the underlying functions (e.g.add).Examples:
>>> q_add = QFunctional() >>> a = torch.quantize_per_tensor(torch.tensor(3.0), 1.0, 0, torch.qint32) >>> b = torch.quantize_per_tensor(torch.tensor(4.0), 1.0, 0, torch.qint32) >>> q_add.add(a, b) # Equivalent to ``torch.ops.quantized.add(a, b, 1.0, 0)``
- Valid operation names:
add
cat
mul
add_relu
add_scalar
mul_scalar
Quantize¶
-
class
torch.nn.quantized.Quantize(scale, zero_point, dtype)[source]¶ Quantizes an incoming tensor
- Parameters
scale – scale of the output Quantized Tensor
zero_point – zero_point of output Quantized Tensor
dtype – data type of output Quantized Tensor
- Variables
zero_point, dtype (`scale`,) –
- Examples::
>>> t = torch.tensor([[1., -1.], [1., -1.]]) >>> scale, zero_point, dtype = 1.0, 2, torch.qint8 >>> qm = Quantize(scale, zero_point, dtype) >>> qt = qm(t) >>> print(qt) tensor([[ 1., -1.], [ 1., -1.]], size=(2, 2), dtype=torch.qint8, scale=1.0, zero_point=2)
DeQuantize¶
-
class
torch.nn.quantized.DeQuantize[source]¶ Dequantizes an incoming tensor
- Examples::
>>> input = torch.tensor([[1., -1.], [1., -1.]]) >>> scale, zero_point, dtype = 1.0, 2, torch.qint8 >>> qm = Quantize(scale, zero_point, dtype) >>> quantized_input = qm(input) >>> dqm = DeQuantize() >>> dequantized = dqm(quantized_input) >>> print(dequantized) tensor([[ 1., -1.], [ 1., -1.]], dtype=torch.float32)
Linear¶
-
class
torch.nn.quantized.Linear(in_features, out_features, bias_=True, dtype=torch.qint8)[source]¶ A quantized linear module with quantized tensor as inputs and outputs. We adopt the same interface as torch.nn.Linear, please see https://pytorch.org/docs/stable/nn.html#torch.nn.Linear for documentation.
Similar to
Linear, attributes will be randomly initialized at module creation time and will be overwritten later- Variables
~Linear.weight (Tensor) – the non-learnable quantized weights of the module of shape .
~Linear.bias (Tensor) – the non-learnable bias of the module of shape . If
biasisTrue, the values are initialized to zero.~Linear.scale – scale parameter of output Quantized Tensor, type: double
~Linear.zero_point – zero_point parameter for output Quantized Tensor, type: long
Examples:
>>> m = nn.quantized.Linear(20, 30) >>> input = torch.randn(128, 20) >>> input = torch.quantize_per_tensor(input, 1.0, 0, torch.quint8) >>> output = m(input) >>> print(output.size()) torch.Size([128, 30])
BatchNorm2d¶
-
class
torch.nn.quantized.BatchNorm2d(num_features, eps=1e-05, momentum=0.1)[source]¶ This is the quantized version of
BatchNorm2d.
BatchNorm3d¶
-
class
torch.nn.quantized.BatchNorm3d(num_features, eps=1e-05, momentum=0.1)[source]¶ This is the quantized version of
BatchNorm3d.
LayerNorm¶
-
class
torch.nn.quantized.LayerNorm(normalized_shape, weight, bias, scale, zero_point, eps=1e-05, elementwise_affine=True)[source]¶ This is the quantized version of
LayerNorm.- Additional args:
scale - quantization scale of the output, type: double.
zero_point - quantization zero point of the output, type: long.
GroupNorm¶
-
class
torch.nn.quantized.GroupNorm(num_groups, num_channels, weight, bias, scale, zero_point, eps=1e-05, affine=True)[source]¶ This is the quantized version of
GroupNorm.- Additional args:
scale - quantization scale of the output, type: double.
zero_point - quantization zero point of the output, type: long.
InstanceNorm1d¶
-
class
torch.nn.quantized.InstanceNorm1d(num_features, weight, bias, scale, zero_point, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)[source]¶ This is the quantized version of
InstanceNorm1d.- Additional args:
scale - quantization scale of the output, type: double.
zero_point - quantization zero point of the output, type: long.
InstanceNorm2d¶
-
class
torch.nn.quantized.InstanceNorm2d(num_features, weight, bias, scale, zero_point, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)[source]¶ This is the quantized version of
InstanceNorm2d.- Additional args:
scale - quantization scale of the output, type: double.
zero_point - quantization zero point of the output, type: long.
InstanceNorm3d¶
-
class
torch.nn.quantized.InstanceNorm3d(num_features, weight, bias, scale, zero_point, eps=1e-05, momentum=0.1, affine=False, track_running_stats=False)[source]¶ This is the quantized version of
InstanceNorm3d.- Additional args:
scale - quantization scale of the output, type: double.
zero_point - quantization zero point of the output, type: long.
torch.nn.quantized.dynamic¶
Linear¶
-
class
torch.nn.quantized.dynamic.Linear(in_features, out_features, bias_=True, dtype=torch.qint8)[source]¶ A dynamic quantized linear module with floating point tensor as inputs and outputs. We adopt the same interface as torch.nn.Linear, please see https://pytorch.org/docs/stable/nn.html#torch.nn.Linear for documentation.
Similar to
torch.nn.Linear, attributes will be randomly initialized at module creation time and will be overwritten later- Variables
Examples:
>>> m = nn.quantized.dynamic.Linear(20, 30) >>> input = torch.randn(128, 20) >>> output = m(input) >>> print(output.size()) torch.Size([128, 30])
LSTM¶
-
class
torch.nn.quantized.dynamic.LSTM(*args, **kwargs)[source]¶ A dynamic quantized LSTM module with floating point tensor as inputs and outputs. We adopt the same interface as torch.nn.LSTM, please see https://pytorch.org/docs/stable/nn.html#torch.nn.LSTM for documentation.
Examples:
>>> rnn = nn.LSTM(10, 20, 2) >>> input = torch.randn(5, 3, 10) >>> h0 = torch.randn(2, 3, 20) >>> c0 = torch.randn(2, 3, 20) >>> output, (hn, cn) = rnn(input, (h0, c0))
LSTMCell¶
-
class
torch.nn.quantized.dynamic.LSTMCell(*args, **kwargs)[source]¶ A long short-term memory (LSTM) cell.
A dynamic quantized LSTMCell module with floating point tensor as inputs and outputs. Weights are quantized to 8 bits. We adopt the same interface as torch.nn.LSTMCell, please see https://pytorch.org/docs/stable/nn.html#torch.nn.LSTMCell for documentation.
Examples:
>>> rnn = nn.LSTMCell(10, 20) >>> input = torch.randn(6, 3, 10) >>> hx = torch.randn(3, 20) >>> cx = torch.randn(3, 20) >>> output = [] >>> for i in range(6): hx, cx = rnn(input[i], (hx, cx)) output.append(hx)
GRUCell¶
-
class
torch.nn.quantized.dynamic.GRUCell(input_size, hidden_size, bias=True, dtype=torch.qint8)[source]¶ A gated recurrent unit (GRU) cell
A dynamic quantized GRUCell module with floating point tensor as inputs and outputs. Weights are quantized to 8 bits. We adopt the same interface as torch.nn.GRUCell, please see https://pytorch.org/docs/stable/nn.html#torch.nn.GRUCell for documentation.
Examples:
>>> rnn = nn.GRUCell(10, 20) >>> input = torch.randn(6, 3, 10) >>> hx = torch.randn(3, 20) >>> output = [] >>> for i in range(6): hx = rnn(input[i], hx) output.append(hx)
RNNCell¶
-
class
torch.nn.quantized.dynamic.RNNCell(input_size, hidden_size, bias=True, nonlinearity='tanh', dtype=torch.qint8)[source]¶ An Elman RNN cell with tanh or ReLU non-linearity. A dynamic quantized RNNCell module with floating point tensor as inputs and outputs. Weights are quantized to 8 bits. We adopt the same interface as torch.nn.RNNCell, please see https://pytorch.org/docs/stable/nn.html#torch.nn.RNNCell for documentation.
Examples:
>>> rnn = nn.RNNCell(10, 20) >>> input = torch.randn(6, 3, 10) >>> hx = torch.randn(3, 20) >>> output = [] >>> for i in range(6): hx = rnn(input[i], hx) output.append(hx)
